Note
Click here to download the full example code
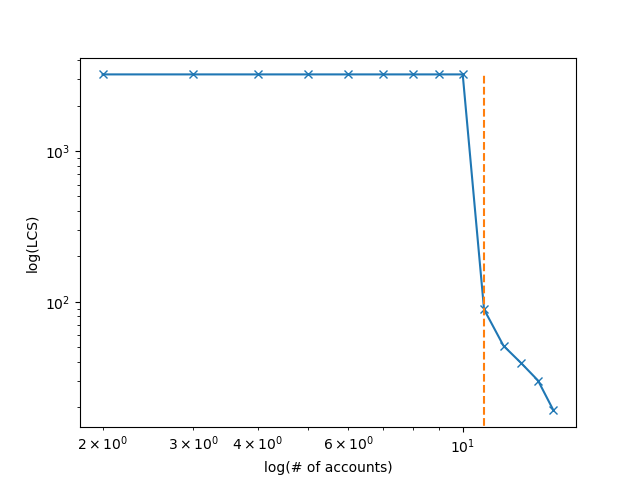
Longest Common Subsequences (log)¶
An example plot of digitaldna.LongestCommonSubsequence
Out:
fitting...
finding cut...
predicting...
done.
from digitaldna import TwitterDDNASequencer
from digitaldna import LongestCommonSubsequence
from digitaldna import Verbosity
import numpy as np
# Generate DDNA from Twitter
model = TwitterDDNASequencer(input_file='timelines.json', alphabet='b3_type')
arr = model.fit_transform()
# Simulate bots by repeating 10 times the first timeline
nrep_arr = [10 if i == 0 else 1 for i in range(len(arr))]
arr = np.repeat(arr, nrep_arr, axis=0)
arr[:, 0] = np.random.randint(0, high=10100, size=len(arr))
# Compute Longest Common Subsequences
estimator = LongestCommonSubsequence(window=2, verbosity=Verbosity.FILE)
estimator.fit_predict(arr[:, 1])
# Plot
estimator.plot_LCS_log()
Total running time of the script: ( 0 minutes 3.665 seconds)